Data Compression and Crowded Pigeons
The Infamous WinZip
Have you ever used a data compression program? WinZip, WinRAR, bzip2 and gzip are all common data compression software. If you have ever emailed large pictures, sent or received text files or pdfs, you may have run across these pieces of software. In general, they take a set of input files, and output a compressed file, which when uncompressed, produce the original files again. The quite amazing thing that these software applications do is to produce a compressed file whose size is less than the sum of the sizes of the input files. This is great! But have you wondered, what would happen if you tried to compress a compressed file? Would it get smaller? Could you not, therefore, repeatedly compress the same file over and over till it became insignificantly small? What is to stop this? Another question you may ask is, given a compressor, can you compress all files to yield a smaller file? Why do some files compress more than others?
The Solution
If you guessed that not all files can be compressed, congrats! In fact, we shall show below that for a given maximum file size, it is mathematically impossible to compress more than 1% of the possible files of that given size by even 1 byte. Want to guarantee another byte? That’s 1% of 1%. How do compressors manage to be so good even though there are so few files that can be compressed? Is there some fundamental limitation that prevents compressors from working on all files? Read on..
Pigeonhole Principle
There is a well-known principle in mathematics and computer science known as the Pigeonhole Principle which is a simple intuitive theorem that says “If you put n pigeons in m pigeonholes, where n > m, then there is at least one pigeonhole with two pigeons in it”. It is a simple counting argument. We shall use this argument below to show how any particular compressor cannot compress all files given to it.
Analysis – Why Compressors Cannot Compress All Files
Let us think of a file as a long string of 1s and 0s. All computer files can essentially be represented by a long series of 0s and 1s. Each digit is known as a bit. We shall call these strings ‘binary strings’. To compress a file, one is taking in a binary input string and outputting a (hopefully shorter) binary output string. Can this be any odd string? No. It must be carefully chosen such that the compression algorithm satisfies a special condition known as invertibility.

Not a compression function
An invertible algorithm is one that produces outputs such that it is possible to convert each output back into the corresponding input string. In formal math, we want the compression algorithm to be a bijection. What this means is that if I provide you with a compression algorithm, it is only valid if I can also provide you a decompression algorithm which takes any of the outputs the compressor produces and converts it back to the corresponding input. Take a look at the figure – a function is mapping 1 to D, 2 to B and both 3 and 4 to A. This cannot be a compression algorithm, because we cannot decompress A. Given A, there is no way to know if the original input was 3 or 4. If invertibility were not present, there would be files that you could compress that you would never be able to decompress (because the decompressor wouldn’t know how to). An essential consequence of this requirement is that the compression routine cannot map two of its inputs to one output string (known in formal mathematics as surjectivity). After all, you wouldn’t want all your country music randomly decompress to electronic music just because your compressor mapped them to the same value now, would you?
This brings us to the crux of our argument. A compression algorithm is only interesting if it produces smaller outputs for at least some of its inputs. Let us try to write a compression algorithm that took any string of length equal to

No Ideal Compression Algorithm
How many total strings are there of length n? Well, let’s start counting them. There is exactly 1 string of length 0 (the empty string – “”). There are 2 strings of length 1 (0 and 1). There are 4 strings of length 2 (00, 01, 10 and 11). There are 8 strings of length 3 so on and so forth. Hence, there are 2^n strings of length exactly equal n.
How many total string are there of maximum length n-1?. The number of strings of a size less than or equal to n-1 is the sum of the number of strings of size 0, 1, 2, …, n-1. This is 1 + 2 + 4 + 8 + … + 2^(n-1). If you carefully do this sum, it comes to 2^n – 1. This is the number of unique strings of size n-1 or smaller. If you followed the argument up to this point, you will notice that there are 2^n strings (of size n) that we are trying to pack within 2^n – 1 available strings of smaller sizes. Applying our pigeonhole principle, in at least one instance, two strings are mapped to the same smaller string. We can now see how we cannot take every string of a given size and guarantee its compression. We can find at least one string that we cannot compress. Realistically, if we want to compress by at least one byte, this gets worse. We would be trying to map 2^n source strings to 2^(n-7) -1 compressed strings. We would only be able to compress 1 in 128 strings.
Compressors in Real Life
Why do compressors work so well in real life? That is because, in real life, files that we want to compress have lots of patterns in them. Text documents have lots of letters and numbers. They contain very common and repeated dictionary words. Large bitmap images have regions of the same or similar colors. Music is rhythmic and orderly. A compressor exploits in patterns in a number of ways. One way is to look at words in your file and to replace big, frequent words with smaller codes. All of these techniques act towards decreasing the number of common patterns in a file. The sort of files that are hard to compress are the ones that are very varied – full of ‘random’ data. Computer code is harder to compress than human text. Already compressed files are very hard to compress due to this reason. The entropy of these files are high, making it hard to represent them in a smaller number of bits in any reasonable scheme. There are no discernible patterns in them, or the patterns are too complicated to effectively represent in a shorter manner. When you compress a compressed file, you usually end up with a larger file.
We have only been talking about a class of compressors called lossless compressors. These compressors must reproduce the source file exactly when decompressed. There is also a form of compression called lossy compression. This compression cannot be exactly reversed. It only approximately produces the source string. Now, an approximate transcript of Shakespeare (with characters and words missing or replaced) is quite unacceptable. But an approximate rendering of your vacation pictures is quite acceptable, especially when given the tremendous memory savings. Lossy compression tends to get better compression ratios, but they do this at the cost of irretrievably throwing away data. These compressors are used to compress music, video and images but not binaries or text. Nevertheless, even these compressors have a tough time compressing random data. The only reason compression algorithms work, is because the data that we want compressed is so utterly repetitive and predictable. Any data that doesn’t satisfy this condition is extremely hard to compress.
Further Reading
- Burrows-Wheeler transform used in bzip2.
- Lempel-Ziv-Welch algorithm
- Huffman coding
- Universal coding
- LZMA used in 7zip.


“mathematically impossible to compress more than 1% of the possible files of that given size by even 1 byte.”
That’s false. For strings of length 1, I can build a trivial compressor that compresses half of the strings to length 0. Your point is right, but using a percentage is wrong. It’s true for any file of particularly meaningful length though :P.
“1 byte” :) Yes, you can compress 50% of strings of length 1 into strings of length 0 (1 bit). You can compress 75% of strings of length 2 into strings of lengths 1 and 0. For large n, you can basically compress all but 1 string of length n into strings of n-1 or smaller. Now, to compress it by a byte, you need to eliminate 8 bits: from the long boring equation above, the percentage of strings to which we can do that is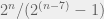 which is roughly
which is roughly 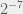 or 1 in 128 or 1%. For an extra byte, the odds are technically
or 1 in 128 or 1%. For an extra byte, the odds are technically 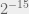 which is less than 1% of 1% (its odds are closer to 1 in 30000) but the statement is still true, albeit a little lax.
which is less than 1% of 1% (its odds are closer to 1 in 30000) but the statement is still true, albeit a little lax.
As a random aside, I love the fact that I can inline latex using $ no-spaces-here latex foo $ but that the image quality looks horrible on my laptop. I should see what it looks like on other browsers/OSes to see if it is just some anti-aliasing fail on my machine.
I would pay real money for compression software that automatically detects country music and randomly decompresses it into electronic music.
Many interview candidates get the Pigeonhole Principle wrong, or fail to recognize it. It’s kind of embarrassing.
Wow, I thought I was targeting this blog towards $girlfriend’s siblings (highschool). Either I’m targeting too high or they are going to kick ass at Google interviews in 5 years.
It’s the Fox News effect. I feel smart because you’re telling me something I already know.